

¿Por qué REST no siempre es el mejor?
By Oscar Diosdado / 03/01/2020 / Tech
DECLARACIÓN DE DIVULGACIÓN: Las opiniones en este contenido reflejan las opiniones del autor. Salvo que se indique específicamente en el artículo, GM Financial no está afiliada, no avala ni está avalada por ninguna de las compañías mencionadas. Todas las marcas comerciales y demás propiedad intelectual utilizadas o mostradas son propiedad de sus respectivos dueños.
El portal de Stratos es una aplicación interna que hemos desarrollado para proporcionar las capacidades de un portal de administración de la nube (CMP) para nuestra nube local alojada en VMware. Es utilizado actualmente por nuestro equipo de arquitectos de TI para solicitar infraestructura como VM y funciones de servidor con el objetivo de que el producto sea un autoservicio para toda la infraestructura local, como reglas de firewall, VIPS y almacenamiento. El portal automatiza la mayoría de los pasos manuales que se producen al entregar la infraestructura desde el inicio hasta el equipo de soporte del servidor que, en última instancia, administra la VM a largo plazo. El portal se construye usando React para el frontend y Node para la API backend. Seguimos los principios de 12 factores que se prestan para ser contenidos y, por lo tanto, ejecutarse en cualquier plataforma alojada.
El problema
Cuando un usuario inicia sesión en el portal para enviar una solicitud para una VM, es guiado hacia un formulario de pedido que crea una carga útil JSON de estos datos que luego se envía al backend.
En la primera iteración de la plataforma, todas las llamadas a los servicios externos, como Infoblox para la administración de la red, Terraform para la clonación de VM, ServiceNow para la administración de CMDB y Puppet para la configuración, fueron manejadas por el backend.
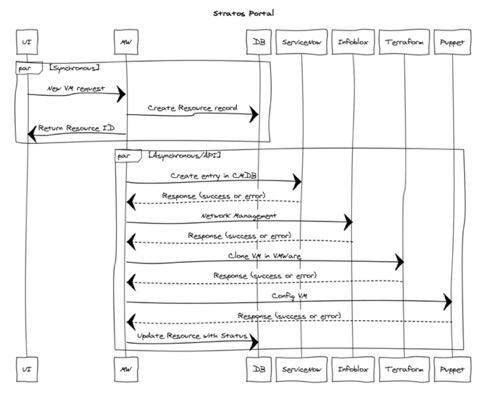
La comunicación desde el frontend, el backend y los servicios de terceros se manejan utilizando REST. Unos meses después de salir en vivo, descubrimos que esto no siempre era ideal para nuestro caso. Esto es lo que aprendimos:
REST no tiene estado
La solicitud de un usuario desde el frontend hasta el backend se maneja de forma sincrónica; la API de backend recibe esta solicitud y, a continuación, hace llamadas para realizar estas acciones de forma asíncrona cuando corresponde.
La creación de una VM tiene pasos que se pueden realizar de forma asíncrona, pero estos se encuentran al final del proceso. Por diseño, la comunicación REST no tiene estado, lo que significa que una vez que la API recibe una solicitud, no debe mantener su estado de cliente en el servidor.
Entonces ¿qué sucede si uno de los servicios de terceros no está funcionando? O bien, ¿si hay un nuevo cambio o mala configuración? O peor ¿qué sucede si nuestro contenedor falla? En nuestra primera iteración de la plataforma, este tipo de cambio o interacción causó que una compilación fallara sin forma de recuperarla.
Una vez que se determinó la causa raíz de la falla, la compilación tuvo que ser retirada de servicio y hubo que realizar nueva solicitud. Esto causó mucho trabajo manual para nuestro equipo y también retrasó a los arquitectos de TI en poder entregar la infraestructura.
La solución
Podríamos haber aprovechado mecanismos de reintento que están disponibles en las bibliotecas REST de nodos, pero esto hubiera solucionado solo uno de nuestros problemas. Las funciones de reintento solo existirían en la transacción única. Una vez agotado el reintento, habríamos perdido esa transacción sin forma de reiniciarla. Lo que necesitábamos era una manera de pausar el proceso cuando se encontraba un error crítico y continuar una vez que se había solucionado. Necesitábamos una solución que rastreara el estado.
Ingrese a Rabbit, MQ
Las colas de mensajes no son una novedad. Los servicios de mensajes Java (JMS) se introdujeron por primera vez en 1998 y el protocolo avanzado de cola de mensajes, que es el estándar para middleware orientado a mensajes, fue creado en 2003 por John O'Hara. Trató de definir un estándar para la orientación de mensajes, la cola y el enrutamiento, así como de introducir fiabilidad y seguridad.
Los mensajes nos permitirían mover transacciones singulares entre funciones, es decir, llamar a la función Terraform con datos de Infoblox para construir una relación el servidor y el mensaje-agente donde un mensaje sería colocado en una cola a la que el trabajador de servicio Terraform se suscribiría. El trabajador procesaría el trabajo necesario y respondería a otra cola para continuar el proceso de compilación.
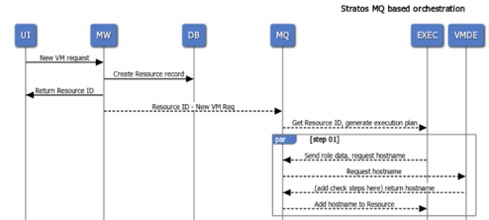
En esta estructura, los servicios de terceros tendrían sus propios trabajadores que se suscribirían a la propia cola del tercero. Un ejecutor sería el orquestador entre los trabajadores y manejaría la creación del mensaje inicial y las actualizaciones al estado del recurso que se está construyendo.
En adelante
Reestructurar una solicitud es bastante difícil y hacerlo a la vez que se proporcionan correcciones de errores a los usuarios finales es aún más difícil. Nuestro enfoque es dividir estos procesos lentamente usando el patrón estrangulador (strangler pattern). Sí, incluso una nueva y brillante aplicación de 12 factores puede convertirse en un monolito. Habrá más información sobre cómo estamos resolviendo esto en los próximos artículos. ¡Manténgase en contacto!
By Oscar Diosdado, GM Financial
Oscar Diosdado is a Senior Software Development Engineer on the Infrastructure & Tooling team out of the Arlington, TX office.
Artículos relacionados

Plataforma de aplicación de código bajo
Utilizamos muchas herramientas y procesos para hacer las cosas en GM Financial, y siempre buscamos maneras de ser más eficientes en nuestro trabajo. Aprenda cómo utilizamos una plataforma de aplicaciones de código bajo para hacer precisamente eso.
LEER MÁS
La Red de Defensores del Cambio
Vea cómo usamos nuestra Red de Defensores del Cambio (Change Advocate Network, CAN) para mejorar nuestras eficiencias y ser más colaborativos.
LEER MÁS